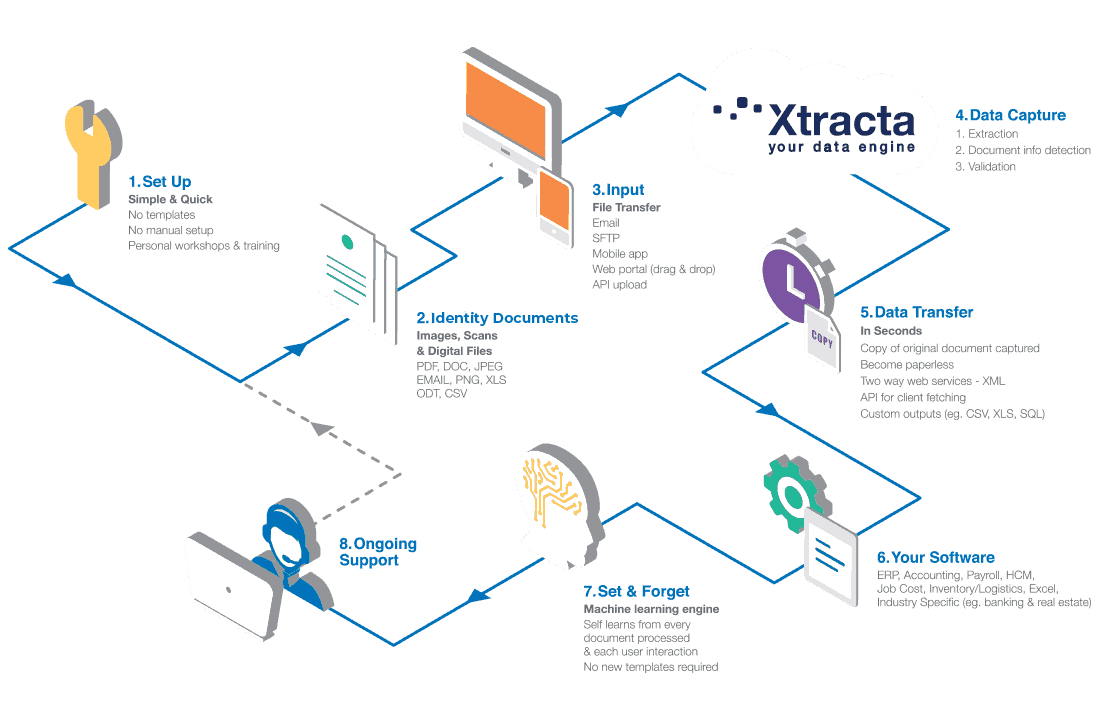
Delivering data how you want it
Helping you save time and money and become paperless with quick, highly accurate automated data capture.
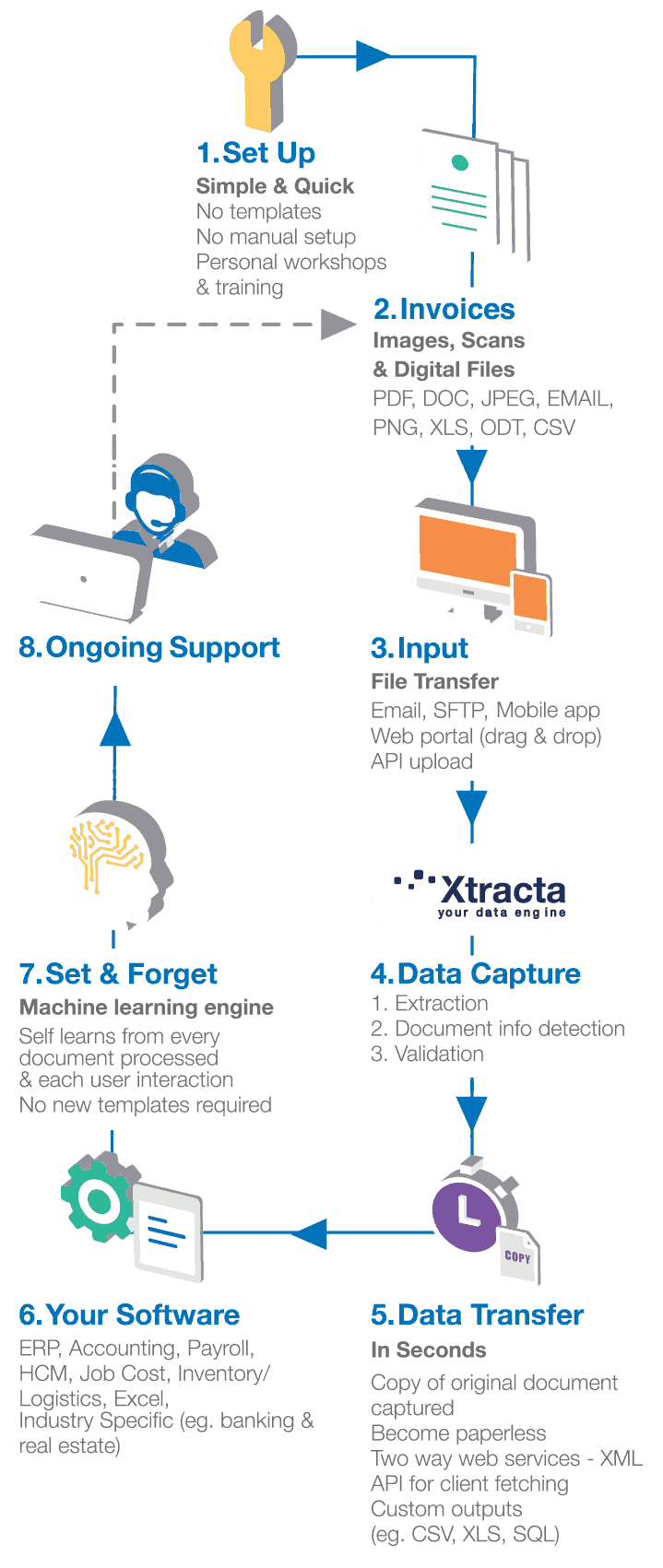
Delivering data how you want it
Helping you save time and money and become paperless with quick, highly accurate automated data capture.
The capture of data from identity documents is becoming an ever more in-demand ability within the applications and processes of many industries. From finance to travel to healthcare, being able to reliably and quickly prove the identity of a customer can allow faster provision of services and the ability to automatically check and process identity documents can reduce administrative overheads. All of this leads to improved customers’ experiences and reduced costs for providers.
Xtracta has an extensive capability to extract data from identity documents such as passports, national IDs, drivers licenses, workplace IDs and more that our customers and partners can build into their processes and solutions. Supporting both embedded (I.e. in-app or in-website etc.) solutions alongside stand-alone identity document processing services, Xtracta can cover the needs of most organizations and industries for identity document data extraction.

The API supports a wide range of identity documents including passports, national identity cards, driver’s licenses, workplace ID cards, travel (passport) visas, vaccination certificates and more. The system comes with pre-trained models for a variety of common identity documents (such as passports) and can be easily trained through a simple click-and-train process for other identity documents to generate extraction models. The user interface also doubles as a validation workflow for low confidence or rejected documents that operators can verify through an embeddable UI opened through an API call or secure web application.
With most documents now being captured via mobile device – such as within dedicated apps, Xtracta provides an image capture SDK to our partners which can be incorporated inside of their apps. Supporting both Android and iOS, the SDK provides features such as automatic cropping, image flattening, deskewing, lighting improvements, camera focus enhancements and more.
Additionally, the image capture SDK supports the creation of multi-page files for extraction – for example capturing the back and front of a drivers’ license as two separate pages so data can be efficiently lifted and combined from both sides of the document.


Xtracta has a comprehensive suite of services including document type auto-detection, splitting and extraction from a huge variety of document types. You can incorporate these services to providing a full-package solution to your customers beyond just identity document extraction. For example, the system can ingest a multi-page PDF which contains application forms, scanned copies of identity documents, proof of address documents etc.. It will separate and classify the document type(s) for each and then extract relevant information from each document type providing a unified data response back to our customers’ applications
Xtracta has a wide range of deployment options. Our public cloud is fast-to-deploy and multi-region with configurable workflows and document images meeting data sovereignty rules. Additionally Xtracta can also be deployed into a private cloud environment or on-premise/client datacentre deployment.

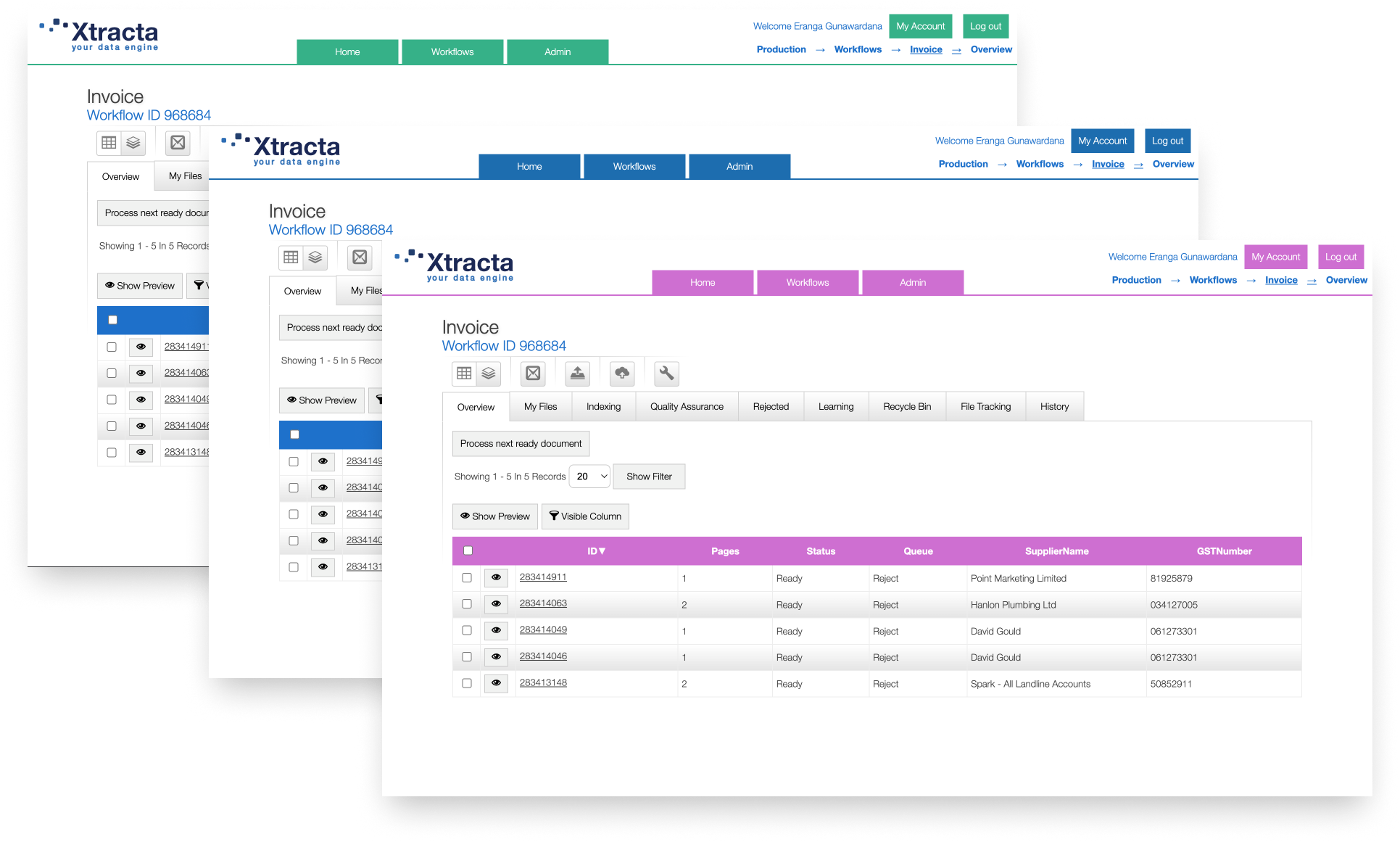
With our easy to use API and brandable solution
With our easy to use API and brandable solution

The Xtracta identity verification API supports all forms of identity documents including virtually all digital formats (PDF, DOC etc.) and imaged documents (PDF, JPG, PNG etc.) Do away with ID scanners and manual data entry. Give users the ultimate flexibility in how they submit ID information to you.


Using Xtracta’s artificial intelligence technology, the identity verification API doesn’t need specialist engineers to set up “rules” or “templates” for each supplier ID card designs. Even if the engine has never seen that ID card before, it can automatically pull all of the information required including line items. You tell the engine what you want and it will capture it.

Powered by artificial intelligence and machine learning technology, Xtracta constantly learns with every new document scanned and every interaction with users. This self-learning ability enables the hands-free data extraction from an unlimited number of document designs in a variety of languages.
In exceptional cases where data may be missing, end-users can also “teach” the engine by simply clicking on data in the Engine Learning Screen to show the Xtracta engine what data they want from the document.
The Xtracta API makes it simple for software companies to integrate the data extraction capabilities into their applications. With full documentation and personalised integration support, and the using of industry standard REST architecture with either JSON or XML data structures – the API can be deployed into desktop, SaaS or mobile apps quickly and efficiently. The system can be completely whitelabelled and be used with our without the UI as needed.



Want to add touchless data capture of high volume documents, like invoices and receipts, to the software you use? We have partners ready to help you.
Join our global partner network.
Get everything you need to sell Xtracta and help your customers automate their data capture.
Want to into integrate Xtracta with your own software? Use our easy to use API and image capture SDK and brand the functionality as your own.
©Xtracta Limited 2026 | Automated Data Capture – Delivering Data How You Want It.











